Use Excel for Two-way ANOVA
Exercise 10.1.5.
Statistics for Ecologists (Edition 2) Exercise 10.1.5
This exercise is concerned with analysis of variance (ANOVA) in Chapter 10. In particular with the situation when you have two predictor variables, that is two-way ANOVA.
Using Excel for two-way ANOVA (analysis of variance)
Introduction
Excel can carry out the necessary calculations to conduct ANOVA and has several useful functions that can help you:
- FDIST – calculates an exact p-value for a given F-value (and degrees of freedom).
- VAR – computes the variance of a series of values.
- COUNT – counts the number of items, useful for degrees of freedom.
- AVERAGE – calculates the mean.
However, Excel is most suitable for one-way ANOVA, where you have a single predictor variable. When you have two predictor variables two-way ANOVA is possible, but can be tricky to arrange.
In order to carry out the calculations you need to have your data arranged in a particular layout, let’s call it sample layout or “on the ground” layout. This is not generally a good layout to record your results but it is the only way you can proceed sensibly using Excel. In this exercise you’ll see how to set out your data and have a go at the necessary calculations to perform a two-way ANOVA.
The data for this exercise are available as a file: Two Way online.xlsx. There are two worksheets, one with the bare data and one completed version so you can check your work.
You can use the Analysis ToolPak to carry out the computations for you but you’ll still need to arrange the data in a particular manner. The Analysis ToolPak is not “active” by default so you may need to go to the options/settings and look for Add-Ins.
The exercise data
The data you’ll use for this exercise are in the file Two Way online.xlsx and are presented in the following table:
Exercise data for two-way anova.
| Water | vulgaris | sativa |
| Lo | 9 | 7 |
| Lo | 11 | 6 |
| Lo | 6 | 5 |
| Mid | 14 | 14 |
| Mid | 17 | 17 |
| Mid | 19 | 15 |
| Hi | 28 | 44 |
| Hi | 31 | 38 |
| Hi | 32 | 37 |
These data represent the growth of two different plant species under three different watering regimes. The first column shows the levels of the Water variable, this is one of the predictor variables and you can see that there are three levels: Lo, Mid and Hi. The next two columns show the growth results for two plant species, labelled vulgaris and sativa. These two columns form the second predictor variable (we’ll call that Plant, which seems suitable).
This layout is the only way that Excel can deal with the values but it is not necessarily the most useful general layout for your data. The scientific recording layout is more powerful and flexible.
The other thing to note is that there are an equal number of items (replicates) in each “block”. Here there are only 3 observations per block. This replication balance is important; the more unbalanced your situation is the more “unreliable” the result is. In fact, if you use the Analysis ToolPak for 2-way ANOVA you must have a completely balanced dataset (or the routine refuses to run).
Calculate Column Sums of Squares
Start by opening the example datafile: Two Way online.xlsx. Make sure you go to the Data worksheet (the worksheet Completed is there for you to check your results). The data are set out like the previous table, in sample layout. You will need to calculate the various sums of squares and to help you the worksheet has some extra areas highlighted for you.
Start by calculating the column SS, that is the sums of squares for the Plant predictor.
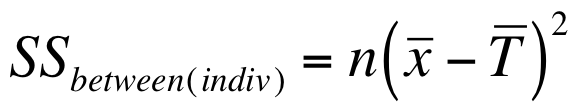
In the formula x represents each column, T is the overall data and n is the number of samples.
- Click in cell A12 and type a label, Col SS, for the sums of squares of the columns (the Plant predictor variable).
- In Cell B12 type a formula to calculate the SS for the vulgaris column: =(AVERAGE(B2:B10)-AVERAGE(B2:C10))^2*COUNT(B2:B10). You should get 7.11.
- In C12 type a similar formula to get the SS for the sativa column: =(AVERAGE(C2:C10)-AVERAGE(B2:C10))^2*COUNT(C2:C10). You should get 7.11.
You should now have the two sums of squares for the columns (the Plant predictor).
Calculate Row Sums of Squares
The row SS are calculated in a similar manner to the col SS.
- In cell E3 type a formula to compute the row SS for the Water block Lo: =(AVERAGE(B2:C4)-AVERAGE(B2:C10))^2*COUNT(B2:C4). You should get 880.07.
- In E6 compute row SS for the Mid block: =(AVERAGE(B5:C7)-AVERAGE(B2:C10))^2*COUNT(B5:C7). You should get 71.19.
- In E9 compute row SS for the Hi block: =(AVERAGE(B8:C10)-AVERAGE(B2:C10))^2*COUNT(B8:C10). You should get 1451.85.
- In E12 calculate the overall row SS: =SUM(E2:E10). You should get 2401.11.
- In F12 type a label, Row SS, to remind you what this value is.
You’ve now got the row and column SS.
Calculate Error Sums of Squares (within groups SS)
The next step is to determine the error sums of squares. You can get this by multiplying the block variance by the number of replicates for each group minus 1. This is essentially a tinkering of the formula for variance:
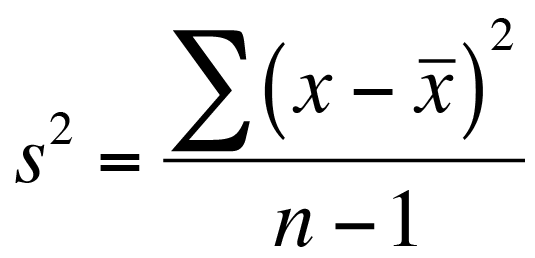
- In H3 type a formula to calculate the SS for the Lo Water and vulgaris Plant block: =VAR(B2:B4)*2. You should get 12.67.
- Repeat the previous step for the rest of the blocks. You’ll need to highlight the appropriate values for each block. Note that the *2 part is the same for all blocks, as there are three replicates for each block.
- In H12 type a formula to calculate the overall error SS: =SUM(H2:I10). You should get 69.33.
- In I13 type a label, Error SS, to remind you what the value represents.
You now have the error term for the ANOVA. This is an important value, as you’ll need it to calculate the final F-values.
Calculate Interaction Sums of Squares
The final SS component is that for the interactions between the two variables (Water and Plant). To do this you use the means of the various groups and the replication like so:
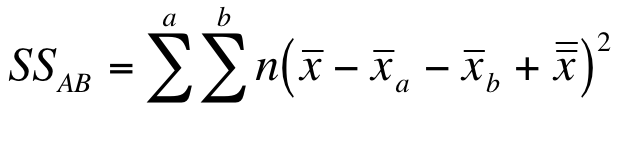
The formula looks horrendouns but in reality it is more tedious than really hard. The first mean is the mean of a single block. The next Xa, is essentially the column mean. The Xb mean is the “row” mean. The final mean (double overbar) is the overall mean. The n is the number of replicates in each block.
- In K3 type a formula for the interaction SS for the fisrt block: =(AVERAGE(B2:B4)-AVERAGE(B2:B10)-AVERAGE(B2:C4)+AVERAGE(B2:C10))^2*COUNT(B2:B4). You should get 14.81.
- In K6: =(AVERAGE(B5:B7)-AVERAGE(B2:B10)-AVERAGE(B5:C7)+AVERAGE(B2:C10))^2*COUNT(B5:B7). Gives 7.26.
- In K9: =(AVERAGE(B8:B10)-AVERAGE(B2:B10)-AVERAGE(B8:C10)+AVERAGE(B2:C10))^2*COUNT(B8:B10). Gives 42.81.
- In L3: =(AVERAGE(C2:C4)-AVERAGE(C2:C10)-AVERAGE(B2:C4)+AVERAGE(B2:C10))^2*COUNT(C2:C4). Gives 14.81.
- In L6: =(AVERAGE(C5:C7)-AVERAGE(C2:C10)-AVERAGE(B5:C7)+AVERAGE(B2:C10))^2*COUNT(C5:C7). Gives 7.26.
- In L9: =(AVERAGE(C8:C10)-AVERAGE(C2:C10)-AVERAGE(B8:C10)+AVERAGE(B2:C10))^2*COUNT(C8:C10). Gives 42.81.
- In K12 type a formula to get the total interaction SS: =SUM(K2:L10). You should get 129.78.
- In L12 type a label, Interact SS, to remind you what the value represents.
Now you have all the sums of squares values you need to complete the ANOVA.
Compute total SS and degrees of freedom
The total sums of squares can be calculated by adding the component SS together. On the other hand, it would be good to check your maths by calculating it from the total variance and df.
You’ll also need the degrees of freedom for the various components before you can construct the final ANOVA table.
- In A13 type a label, Total SS, for the overall sums of squares.
- In B13 type a formula to calculate the total SS: =VAR(B2:C10)*(COUNT(B2:C10)-1). You should get 2616.44.
- In A14 type a label, df, for the degrees of freedom.
- In B14 type a formula for the column df: =COUNT(B12:C12)-1. The result should be 1.
- In E14 type a formula for row df: =COUNT(E2:E10)-1. You should get 2.
- In H14 work out the error df: =C18*C19. You should get 2.
- In K14 work out the interaction df: =COUNT(B2:C10)-COUNT(K2:L10). You should get 12.
Now you have everything except the total df, which you can place in the final ANOVA table shortly.
Make the final ANOVA table
You can now construct the final ANOVA table and compute the F-values and significance of the various components. You want your table to end up looking like the following:
Completed anova table for two-way analysis of variance.
| ANOVA | ||||||
| Source of Variation | SS | df | MS | F | P-value | F crit |
| Water | 2403.1 | 2 | 1201.56 | 207.96 | 4.9E-10 | 3.89 |
| Plant | 14.22 | 1 | 14.22 | 2.46 | 0.1426 | 4.75 |
| Water*Plant | 129.78 | 2 | 64.89 | 11.23 | 0.0018 | 3.89 |
| Error | 69.33 | 12 | 5.78 | |||
| Total | 2616.44 | 17 |
- Start by typing a label, ANOVA, into cell A16.
- Type the rest of the labels for the ANOVA table as shown above.
- In the SS column you can place the sums of squares results, which you’ve already computed. So in B18: =E12. In B19: =SUM(B12:C12). and so on.
- The total SS can be =B13 or a sum of the individual SS components.
- In the df column you can place the values, which are already computed. The total SS in C22 needs to be determined: =COUNT(B2:C10)-1. You should get 17.
- The MS are worked out by dividing the SS by the df. For e.g. in D18: =B18/C18.
- Determine an F-value by dividing the MS for a row by the Error MS. So in E18: =D18/D21. Gives 207.96.
- Work out an exact p-value for each of your F-values using the FDIST function. You need your F-value, the df for that row and the error df. In F18 type: =FDIST(E18,C18,C21). The result should be 4.9E-10, which is highly significant.
- In F19: =FDIST(E19,C19,C21).
- In F20: =FDIST(E20,C20,C21).
- You can use the FINV function to get a critical value for F. You’ll need a level of significance (0.05), the df for that row and the error df. In G18 type: =FINV(0.05,C18,C21). The result is 3.89.
- In G19: =FINV(0.05,C19,C21).
- In G20: =FINV(0.05,C20,C21).
Now you have the final ANOVA table completed. You can see that the interaction term is highly significant (p = 0.0018). The Water treatment is also significant but the Plant variable is not (p = 0.14).
Graphing the result
You should plot your result as a chart of some kind. There are several ways you might proceed. Chapter 6 gives details about constructing charts in Excel and in R for various scenarios.
One option would be to make a bar chart, showing the mean for each block, and with the blocks grouped by watering treatment or by plant species. You should give an impression of the variability using error bars. The following column chart was produced using 95% confidence intervals:

Visualisation of two-way anova result. Bars show sample means and error bars are 95% CI.
The critical value for t can be determined using the TINV function and the degrees of freedom: =(TINV(0.05,16)). Note that in this case df = 16 because we are splitting the blocks by plant (there are 9-1 + 9-1 = 16 degrees of freedom). The size of the error bars is then:
Standard Error * t-crit.
Comments are closed.