Preparing & managing community data
Exercise 12.0.0.
Statistics for Ecologists (Edition 2) Exercise 12.0.0
This exercise relates to all of Chapter 12 (community ecology), and is primarily aimed at helping you to prepare data and assemble it in a form that allows you to carry out further investigation. This follows on from an earlier exercise in Section 3.2.7, where you used an Excel Pivot Table.
Preparing & managing community data
Introduction
I am text block. Click edit button to change this text. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
It is important that your data are arranged and set out in a manner that allows you to carry out the analyses that you require. In general, a scientific recording layout is a good starting point (see Section 2.2). In the scientific recording layout (a.k.a. biological recording layout) you have a column for each variable (e.g. site name, species name, abundance). For most purposes this is the most “robust” way to record your data, as you can use the data most flexibly. For community analyses however, you’ll generally want to have the data arranged by site and species, with the rows being site names and the columns the species (with the body of the table being the abundance).
This exercise shows you how to take a dataset that is in recording layout and convert to community layout. Get the datafile for this exercise: Preparing and managing community data exercise.xlsx.
The exercise data
The exercise data are in the file Preparing and managing community data exercise.xlsx. There are several worksheets, with the Data tab being the main data. The other worksheets contain a note about the Domin scale (an ordinal scale of plant abundance), a completed Pivot Table and a dataset ready for export as CSV.
The data show the abundance of some terrestrial plant species at ten sites in Shropshire. These data are part of a series of NVC surveys carried out by student groups. Here are the first few rows of the dataset:
The first few rows of the example dataset.
| Site | Species | Const | Cover | Imp |
| ML1 | Achillea millefolium | 5 | 6 | 6 |
| ML1 | Centaurea nigra | 5 | 4 | 4 |
| ML1 | Lathyrus pratensis | 5 | 5 | 5 |
| ML1 | Leucanthemum vulgare | 5 | 5 | 5 |
| ML1 | Lotus corniculatus | 5 | 7 | 7 |
| ML1 | Plantago lanceolata | 5 | 5 | 5 |
The data are as follows:
- Site = Site names as a simple label.
- Species = Plant species names.
- Const = Frequency of occurrence (a value from 0-5).
- Cover = The maximum abundance in Domin scale (a value from 1-10) from the 5 quadrats at each site.
- Imp = A combination of Const and Cover (Const * Cover ÷ 5) to give an abundance score.
These data are set out in scientific recording layout, that is, each column is a single variable and each row is a “record”. This gives the most flexibility and maximises the usefulness of the data. However, for community analysis we’ll need the data in community layout like so:
The example data laid out as a community dataset. Each column is a separate sample.
| Species | ML1 | ML2 | MU1 | MU2 | PL2 | PU2 | SL1 | SL2 | SU1 | SU2 |
| Achillea millefolium | 6 | 3 | 5 | 4 | 0 | 3.2 | 0 | 0 | 0 | 0 |
| Aegopodium podagraris | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.6 | 0 | 0 |
| Agrostis capillaris | 0 | 8 | 8 | 5.6 | 8 | 0 | 5 | 2 | 3.2 | 0 |
| Agrostis stolonifera | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0.4 | 0 | 0 |
| Anthriscus sylvestris | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.2 | 3 |
| Arctium minus | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.4 |
In this case the columns are the sites. It is easy to transpose the data, either in Excel or later on if you have exported the data to CSV.
Although this is the “ideal” layout for the purpose of community analysis there are other ways to manage the data, which you’ll see as you work through the exercise. The manipulations are illustrated using Excel 2013 (Windows) but you can follow along with most versions of Excel as well as Open Office or Libre Office.
Make a Pivot Table
The starting point for your data arrangement and management is a Pivot Table. This will allow you to arrange and rearrange your data in many (useful) ways. You can also use a Pivot Table to get summary information and to make exploratory graphs.
In Excel 2013 the Pivot Table button is in the Insert ribbon menu. In other spreadsheets you may find the appropriate function in the Data menu. Start by making a new blank Pivot Table in a fresh worksheet:
- Click once anywhere in the block of data; there is no need to highlight or select any data.
- Click the Insert > Pivot Table
- The Create Pivot Table dialogue box should open and you’ll see that the data are automatically selected. The default is to place the new pivot table in a new worksheet so you can simply click OK.
You should now see the new (empty) pivot table and the Pivot Table Fields dialogue box. In most versions of Excel you drag the items you want from the top (the list of variables) to the appropriate section at the bottom of the dialogue window (in some spreadsheets you drag items directly to the pivot table).
Now you are ready to build your dataset. There are many options and in the following exercise you’ll get to see several ways to present the data.
Make species lists
There are various simple lists you can make.
All species present
A good starting point would be to make a list of all the species present across the survey sites.
- Click on the pivot table (currently empty) to ensure that the Pivot Table Field dialogue box opens.
- Now drag the Species field from the list at the top to the area labelled Rows at the bottom of the dialogue box.
Now you have a simple overall species check-list. This is useful as a data validation tool, as you can look through it for spelling mistakes (two entries that are similar, one will probably be a mistake).
Species listed by site
It would also be useful to have a list of the species at each site. There are two ways you could try:
- List all sites with their species
- List sites and their species sequentially
Listing all the sites seems the most obvious.
- Click the Pivot Table to open the Pivot Table Field dialogue box.
- Drag the Site field item from the top to the Rows area at the bottom. Make sure that the Site item is above the Species item (you can drag to rearrange them anytime).
Now you have a compact table showing the species lists for all the sampling sites:
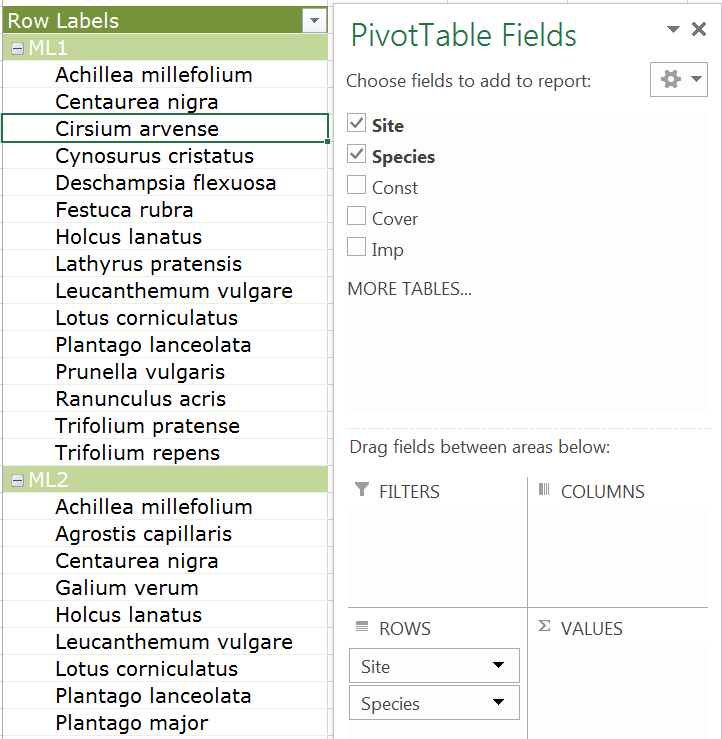
Species lists per sample site.
Try dragging the Site field so that it is underneath the Species field in the Rows area. You now get a list of which sites each species was present in.
You might also want to display a single site, rather than all of them. There are two simple options:
- Filter the Site field to display one (or more) of the sites.
- Move the Site field to the Filters area (sometimes called Report Filter), where you can apply the filter.
The first option allows you to keep the species lists separate per site.
- Click the pivot table to activate the Pivot Table Field dialogue box.
- Move the mouse over the Site field at the top of the Pivot Table list. You’ll see a triangle at the right end of the highlight, click that to open a sort & filter dialogue box.
- Click the box(es) beside the items you want to view or not. A ticked box will be displayed and an empty box will be not displayed!
- Click OK when you are done to apply the filter. Note that you’ll see a funnel icon by the Site field in the list area.
The second option allows you to combine lists across sites.
- If you applied a filter earlier clear it now. Click the Pivot Table then the triangle in the Site field to open the sort & filter dialogue.
- Click the Clear Filter from “Site” button to remove the filter.
- Now drag the Site field from the Row area at the bottom to the Filter area.
- Now you see the top of the pivot table read Site and to the right a label (All) and a grey triangle.
- Click the triangle to open the filter dialogue.
- If you click a single item, you’ll display the species for that site. If you click several sites, you’ll display a list encompassing all those sites.
This approach could be useful if you have “grouped” samples, perhaps from different habitats.
Presence-absence lists
Simple species lists are useful but for calculations of species richness or similarity you’ll need to make a presence-absence dataset. That is one where each species has a 1 for presence or 0 for absence.
This is easily done with the pivot table.
- If you have filters applied they will usually be cleared if you move a field to a new location. Alternatively, you can remove the fields and start afresh (drag the fields out of the lower part of the Pivot Table Field dialogue box or un-tick the fields in the list at the top).
- Drag the Species field to the Rows area.
- Drag the Sites field to the Columns area.
- Now you have a table arranged in a sensible fashion but no data! Drag the Species field from the list at the top to the Values area at the bottom (of the Pivot Table Field dialogue box).
Now you’ll have a table where the presence of species is shown by a 1. The absences are blank spaces. At the moment you’ll also have row and column totals.
- Row totals show the frequency of each species across the samples.
- Column totals show the species richness for each site.

If you need to carry out analysis, then you may well wish to remove the totals and also to replace the blank cells with 0. To do this you’ll need to use the Pivot Table Tools menus.
- Click once in the pivot table to activate the Pivot Table Tools ribbon menus. In Excel 2013 there are two: Analyze and Design. In older versions there were three menus but you should not have too much difficulty finding the right buttons.
- Remove the totals using the Design Click Grand Totals > Off for Rows and Columns.
- To replace blanks with 0 you need the Analyze Click Pivot Table > Options to open the Pivot Table Options dialogue box.
- On the Layout & Format tab (this should be in view by default) enter a 0 in the box labelled For empty cells show. The tick-box beside the label needs to be ticked but this is usually already activated.
- Now click OK to apply the changes.
Now your data are in a form that could be exported as CSV, although you’d need to remove the first three rows from the final CSV.
If you need to have the sites as rows, then you can simply rearrange the fields between the Rows and Columns areas. If you are going to use R then there is no need to do this as you can easily transpose data using the t() command.
Abundance lists
Since these data are accompanied by abundance data it is most likely that you’ll want to use the abundance instead of presence-absence. In the dataset the Imp variable is a measure of abundance derived from the frequency and maximum (Domin) cover. Each sample site is a combination of 5 quadrats but the individual quadrat data is not available.
To make an abundance-based community dataset you simply rearrange the pivot table:
- Click once on the pivot table.
- Now rearrange the fields so that Species are in the Rows area.
- Make sure the Site field is in the Columns area.
- Remove the item in the Values area; just drag it away and it’ll disappear.
- Drag the Imp field from the list at the top to the Values area at the bottom.
The Values item should read Sum of Imp. Since there is only one value per species/site combination this is fine. If the field does not show Sum, then click on it and use Value Field Settings to alter the summary to Sum.
You can arrange the Site and Species fields in different ways, just as you did when making simple lists. Try it out and see what you get. The most useful arrangement for community analysis is where you have Sites as columns and Species as rows. If you need to have the sites as rows, then you can simply rearrange the fields between the Rows and Columns areas. If you are going to use R then there is no need to do this as you can easily transpose data using the t() command once you have the data in R.
Constancy tables
A constancy table is used to display the survey results of a British NVC plant survey. For each site/sample the species are listed. The abundance data are given as a pair of values:
- The constancy – that is the frequency of occurrence (1-5, absences are not shown).
- The cover – that is the maximum abundance from the 5 sample quadrats) in domin scale (1-10).
Even if you are not reporting an NVC survey the process will help to show you how flexible the pivot table can be.
- Start by removing any previous data from the Pivot Table.
- Drag the Species field to the Rows area.
- Drag the Site field to the Columns area.
- Now drag the Const field to the Values area. You now have a table showing the frequency of each species by site.
- Now drag the Cover field to the Values area; drop it underneath the Sum of Const item that’s already there.
Now you have a table showing the Constancy (Frequency) and Cover (max abundance) for each species and site. This is not the most “readable” of tables, so try some modifications.
Try dragging the Site item in the Columns area so that it is underneath the ∑Values item. Now you have two tables side by side, one showing constancy, the other cover.
Move the Site item again, this time place it above the Species item in the Rows area. Now you have a much more useable table, with the sites being shown atop one another.
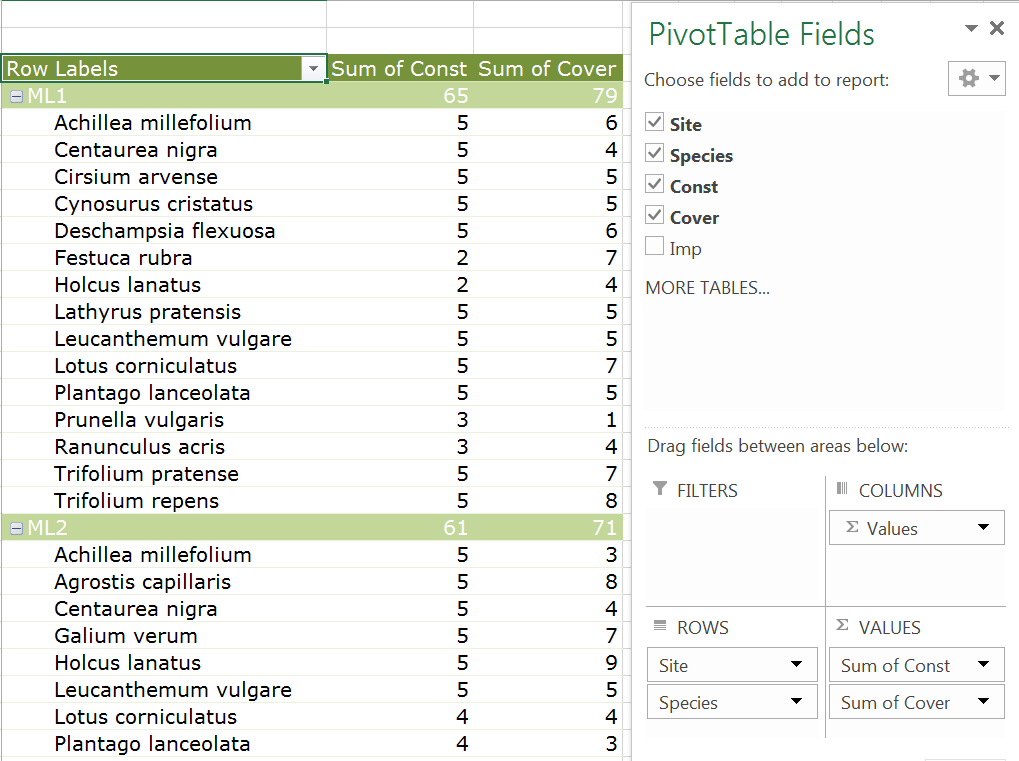
With a bit of tweaking you can recreate the original data layout!
- Click once on the pivot table to activate the Pivot Table Tools
- Click the Design > Report Layout button and select Show in Tabular Form.
- Now click the Report Layout button again and select Repeat All Item Labels.
- Click the Design > Subtotals button and select Do Not Show Subtotals.
Obviously it is a little silly to recreate the original dataset; this just goes to show how you can arrange and rearrange the data easily using a pivot table.
There is a lot more to Pivot Tables (as well as general data management) in my book Managing Data Using Excel!
Comments are closed.